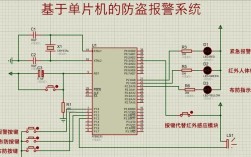
下面我将从核心理念、关键技术栈、具体实践步骤三个层面来详细阐述nb替换需要哪些技术。

(图片来源网络,侵删)
核心理念转变
在谈论具体技术之前,首先要理解为什么需要替换,这背后是工作流理念的转变:
- 从“探索式”到“工程化”:Notebook非常适合探索性数据分析(EDA),快速迭代想法,但工程项目需要的是可重复性、可测试性、可维护性。
- 从“一人一机”到“团队协作”:Notebook是二进制文件,版本控制(如Git)冲突严重,难以进行Code Review,工程化的代码则非常适合团队协作。
- 从“手工执行”到“自动化”:Notebook的执行依赖于手动点击“Run All”或特定单元格,难以集成到CI/CD流水线中,工程化的代码可以轻松地通过脚本、调度器(如Airflow)或CI/CD来自动化执行。
目标:将Notebook中的分析逻辑、数据处理和模型训练代码,剥离出来,转化为标准化的、模块化的Python脚本。
关键技术栈
替换nb的技术栈通常围绕以下几个核心领域构建:
代码组织与管理
这是最基础也是最关键的一步,目标是把Notebook中一个巨大的代码块,拆分成结构清晰的模块。

(图片来源网络,侵删)
-
Python 模块化:
- 技术: 纯Python。
- 实践: 将功能拆分到不同的
.py文件中。src/data_processing.py: 包含所有数据加载、清洗、转换的函数。src/model_training.py: 包含模型定义、训练、评估的函数。src/utils.py: 包含各种辅助函数,如日志、配置加载等。
- 工具: 使用
pip和requirements.txt(或pyproject.toml,poetry) 来管理项目依赖。
-
项目结构模板:
- 技术: Cookiecutter 等项目模板工具。
- 实践: 使用社区公认的数据科学项目结构,
cookiecutter-data-science,它能帮你快速搭建一个规范的项目骨架。project_name/ ├── src/ │ ├── __init__.py │ ├── data_processing.py │ └── ... ├── notebooks/ # (可选) 存放原始的探索性Notebook或最终报告 ├── tests/ ├── data/ │ ├── raw/ │ └ processed/ ├── models/ └── README.md
自动化与工作流编排
当你的分析流程变得复杂,涉及多个步骤时,就需要工具来自动化执行。
-
任务调度/工作流管理:
 (图片来源网络,侵删)
(图片来源网络,侵删)- 技术: Apache Airflow, Dagster, Prefect, Luigi。
- 实践: 将你的分析流程定义为一个有向无环图,一个任务可能是“从数据库下载数据”,另一个任务是“清洗数据”,第三个任务是“训练模型”,Airflow可以确保这些任务按顺序执行,并处理失败、重试等逻辑。
- 优点: 实现端到端的自动化,易于监控和调试。
-
命令行工具:
- 技术: Click, Typer。
- 实践: 为你的脚本创建一个简单的命令行接口。
python train.py --model-type xgboost --epochs 100,这使得脚本可以被其他程序或人方便地调用。
版本控制与协作
这是团队开发的基石。
-
版本控制系统:
- 技术: Git。
- 实践: 所有
.py代码文件都纳入Git进行版本控制,配合GitHub/GitLab进行代码托管和协作。
-
代码审查:
- 技术: GitHub Pull Requests (PRs), GitLab Merge Requests。
- 实践: 团队成员通过PR来审查代码的变更,保证代码质量,是知识传递和代码所有权的重要环节。
-
实验跟踪:
- 技术: MLflow, Weights & Biases (W&B), DVC (Data Version Control)。
- 实践: 当你运行训练脚本时,MLflow会自动记录超参数、指标、模型文件、代码版本等信息,这解决了“我上次跑的好结果是怎么得到的?”这个经典问题。
数据与模型管理
数据和模型是数据科学项目的核心资产,需要被有效管理。
-
数据版本控制:
- 技术: DVC (Data Version Control)。
- 实践: DVC使用Git来跟踪指向大型数据集的指针,而不是将数据本身存入Git,这让你可以像管理代码一样管理数据集的版本。
-
模型注册中心:
- 技术: MLflow Registry, S3/GCS, Hugging Face Hub。
- 实践: 将训练好的模型存放在一个中心化的仓库中,可以方便地查询、获取、部署特定版本的模型。
测试
保证代码质量的关键。
-
单元测试:
- 技术:
pytest,unittest。 - 实践: 为你的每个函数(如数据清洗函数)编写测试用例,确保它在各种输入下都能按预期工作。
pytest因其简洁和强大的功能而成为事实标准。
- 技术:
-
集成测试:
- 技术:
pytest+ 临时数据库。 - 实践: 测试多个模块组合在一起时是否能正常工作,测试数据加载模块和数据处理模块能否协同工作,通常使用内存数据库或临时文件来隔离测试环境。
- 技术:
文档与知识沉淀
好的文档是项目成功的一半。
-
文档生成:
- 技术: Sphinx, MkDocs, Jupyter Book。
- 实践: 从代码的docstring(文档字符串)中自动生成API文档,并可以结合Markdown编写更详细的项目说明。
-
叙事性文档:
- 技术: Quarto, Jupyter Book。
- 实践: 这是一种介于代码和文档之间的“中间地带”,你可以用Markdown编写报告,然后通过代码块嵌入Python/R代码来执行并生成图表和结果,Quarto是Jupyter生态的下一代解决方案,非常适合将分析结果转化为可复现的报告或网页。
具体实践步骤(一个可行的迁移路径)
假设你有一个复杂的EDA.ipynb,想要将其重构,可以遵循以下步骤:
-
解构Notebook:
- 打开你的Notebook,将代码按功能逻辑拆分成几个大的块:
- 块A: 配置和依赖导入。
- 块B: 数据加载。
- 块C: 数据探索和可视化。
- 块D: 数据预处理和特征工程。
- 块E: 模型训练和评估。
- 打开你的Notebook,将代码按功能逻辑拆分成几个大的块:
-
创建项目骨架:
- 使用
cookiecutter创建一个标准项目结构。 - 创建
src目录,并根据上面的块创建对应的.py文件(load_data.py,preprocess.py,train.py等)。
- 使用
-
代码移植与重构:
- 将Notebook中的代码逐块移植到对应的
.py文件中。 - 重构:将Notebook中“面条式”的代码,封装成可复用的函数,添加类型注解和详细的docstring。
- 参数化:将硬编码的路径、参数(如文件路径、模型超参数)提取出来,放到配置文件(如
config.yaml)中,通过代码读取。
- 将Notebook中的代码逐块移植到对应的
-
添加测试:
- 为每个新创建的函数编写
pytest测试用例,测试一个数据清洗函数是否能正确处理缺失值。
- 为每个新创建的函数编写
-
创建入口脚本:
- 在项目根目录创建一个
main.py或run.py文件。 - 在这个文件中,按顺序调用你刚刚创建的各个模块的函数,实现整个分析流程的自动化。
- 使用
Click或Typer为这个脚本添加CLI参数。
- 在项目根目录创建一个
-
引入实验跟踪:
修改你的训练脚本,在关键步骤(如开始训练、评估结束时)加入MLflow的记录代码。
-
版本控制与协作:
- 初始化Git仓库,将所有代码文件(包括配置文件)提交。
- 设置GitHub/GitLab,开启CI/CD(每次有代码提交时,自动运行
pytest进行测试)。
-
将原始Notebook归档:
- 将原始的
.ipynb文件移动到项目中的archive/或notebooks/目录下,并添加清晰的注释说明其作用,它不再作为可执行的代码,而是作为探索过程的记录或最终报告的草稿。
- 将原始的
| 传统Notebook工作流 | 替换后的工程化工作流 |
|---|---|
| 文件 | my_analysis.ipynb (一个巨大文件) |
| 执行 | 手动点击 "Run All" |
| 依赖管理 | 手动安装,容易遗漏 |
| 版本控制 | Git冲突严重,难以协作 |
| 实验记录 | 散落在Notebook的cell输出中 |
| 测试 | 无 |
| 文档 | Markdown cell |
| 数据/模型 | 文件名后缀v1, v2 |
nb替换的本质,就是将数据科学工作流从一个“个人探索工具”转变为一个“标准软件工程项目”,这需要综合运用模块化编程、自动化工具、版本控制、测试和实验跟踪等一系列技术,最终目标是实现可复现、可协作、可维护的数据科学实践。