下面我将从核心原理的内在限制、实践中的技术挑战以及应用生态的宏观问题三个层面,详细剖析LoRA技术中存在的问题。

(图片来源网络,侵删)
核心原理的内在限制
这些问题源于LoRA“低秩分解”这一核心思想本身。
低秩假设的局限性
- 问题所在:LoRA的核心假设是,预训练模型的权重矩阵在适应新任务时,其变化部分可以用一个低秩矩阵来有效近似,这个假设在很多情况下是成立的,因为它假设了不同任务之间知识共享的“冗余性”。
- 何时失效:
- 高度专业化或复杂的任务:对于一些与预训练数据分布差异极大、需要模型学习大量全新且独立知识的任务(一个极其小众的领域知识库问答),模型权重的变化可能无法用低秩矩阵来捕捉,强行使用LoRA可能会导致信息丢失,性能反而不如全参数微调。
- 需要注入大量新知识的场景:当需要模型学习大量与原有知识无关的新概念或事实时,低秩分解可能无法提供足够的“容量”来表达这些全新的、独立的模式。
信息损失与性能天花板
- 问题所在:由于LoRA强制将权重变化限制在低秩子空间内,它本质上是一种有损压缩,对于那些需要高秩(即更复杂、更多样化)变化的任务,LoRA会不可避免地丢失一部分信息。
- 表现:在某些任务上,LoRA的最终性能上限会低于全参数微调,它是一种在“性能”和“效率”之间的权衡,当对性能要求达到极致时,LoRA可能不是最优选择。
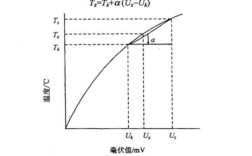
对秩的选择高度敏感
- 问题所在:LoRA的超参数
r(秩)直接决定了可训练参数的数量和模型的适应能力。r的选择是一个典型的“跷跷板”问题:r太小:模型容量不足,无法有效学习任务,导致欠拟合。r太大:参数量增加,微调成本上升,优势减弱,甚至可能因为过度拟合训练数据而出现过拟合。
- 挑战:找到一个全局最优的
r值非常困难,对于不同的模型(如LLaMA vs. Mistral)和不同的任务(如文本生成 vs. 情感分析),最优的r可能差异巨大,这通常需要大量的实验和调参,增加了使用门槛。
实践中的技术挑战
这些问题是开发者在实际使用LoRA时会直接遇到的。
超参数调优的复杂性
除了秩r,LoRA还有其他关键超参数,它们的组合使得调优过程变得复杂:
- Alpha ():这是一个缩放因子,用于平衡原始预训练权重和LoRA权重更新之间的关系,通常设置为
r的倍数(如α = 2r),但最佳比例需要实验确定。 - Target Modules:需要精确指定要对模型的哪些层(如
q_proj,k_proj,v_proj,o_proj等注意力层,或gate_proj,up_proj等MLP层)应用LoRA,选择哪些层、是否对所有层都应用,都会显著影响最终效果,错误的选择可能导致微调失败或效果不佳。 - 学习率:LoRA的学习率设置也不同于全参数微调,通常需要更精细的调整。
负迁移风险
- 问题所在:LoRA在更新特定模块权重的同时,保持了大量原始预训练权重不变,这可能导致模型在适应新任务的同时,意外地“遗忘”或“干扰”了其在原始任务上已经学到的通用能力,这种现象被称为负迁移。
- 表现:模型在特定下游任务上表现很好,但在通用基准测试(如MMLU, HellaSwag)上的得分反而下降了,这是因为LoRA的更新可能与模型原有的、经过海量数据训练的复杂权重分布产生了冲突。
多任务/多LoRA管理困难
- 问题所在:虽然LoRA的一个巨大优势是可以在不存储多个完整模型副本的情况下切换不同任务的适配器,但在实践中,管理成百上千个LoRA权重文件本身也成了一项挑战。
- 表现:
- 存储与命名:需要为每个LoRA文件建立清晰的命名和版本管理规范,否则会变得混乱。
- 加载与切换:频繁地在内存中加载和卸载不同的LoRA文件会增加延迟,尤其是在资源受限的环境中。
- 组合使用:当需要同时激活多个LoRA(一个用于风格,一个用于知识)时,如何安全、有效地合并它们的权重,目前缺乏一个标准化的、高效的解决方案。
量化与兼容性问题
- 问题所在:为了进一步压缩模型,通常会对LoRA进行量化(如4-bit, 8-bit),这会引入新的问题:
- 性能下降:量化过程会引入精度损失,可能削弱LoRA带来的性能提升。
- 兼容性:不同量化库(如bitsandbytes, GPTQ, AWQ)的格式不统一,一个用
bitsandbytes量化的LoRA可能无法直接被其他工具加载,形成了新的生态壁垒。
应用生态的宏观问题
这些问题关乎LoRA技术在整个AI生态中的定位和发展。

(图片来源网络,侵删)
“魔咒”效应与过度依赖
- 问题所在:LoRA的易用性使得许多开发者跳过了对模型本身和任务需求的深入思考,直接套用LoRA进行微调,这可能导致一种“银弹”心态,即认为LoRA是解决所有适配问题的万能钥匙。
- 风险:开发者可能忽略了更根本的问题,如数据质量、任务定义的合理性,或者在某些情况下,全参数微调或其它适配方法(如Prefix-Tuning, Adapter)可能是更合适的选择。
知识产权与模型溯源的模糊性
- 问题所在:一个用LoRA微调的模型,其“主体”仍然是庞大的预训练模型(如Llama 3),而LoRA文件只是其微小的“补丁”,这在法律和伦理上带来了模糊地带:
- 版权归属:基于闭源预训练模型(如Llama, Claude)创建的LoRA模型,其版权和使用权如何界定?使用者是否需要遵守原模型的许可证?
- 责任归属:如果LoRA微调后的模型输出了有害内容,责任方是原始模型开发者、LoRA创建者,还是使用者?这种责任的分散使得追责变得困难。
社区生态的碎片化
- 问题所在:Hugging Face等平台上涌现出海量的LoRA权重文件,这虽然促进了知识共享,但也导致了严重的碎片化。
- 表现:
- 质量参差不齐:大量LoRA缺乏详细的说明、评估指标和可复现的实验设置,用户难以判断其优劣。
- “炼丹”文化:社区过度关注生成各种新奇、有趣但缺乏实用价值的LoRA(如特定角色、画风),而较少关注解决实际工业级问题的、高质量、可复用的LoRA。
LoRA无疑是一项革命性的技术,它极大地降低了大模型微调的门槛,促进了AI的民主化,它并非完美无缺。
| 问题类别 | 核心问题 | 潜在影响 |
|---|---|---|
| 内在限制 | 低秩假设的局限性、信息损失 | 在复杂任务上性能有上限,不适合所有场景 |
| 技术挑战 | 超参数调优复杂、负迁移风险、多任务管理困难 | 增加使用门槛,可能损害模型通用能力,管理成本高 |
| 生态问题 | “魔咒”效应、IP归属模糊、社区碎片化 | 可能导致技术滥用、法律风险、资源浪费 |
未来的发展方向可能会集中在:
- 自适应秩选择:开发算法来自动确定最优的秩
r,减少人工调参。 - 结构化LoRA:探索比简单低秩分解更复杂的结构,以提升模型容量和性能。
- 更鲁棒的训练方法:设计新的训练目标或正则化方法,以减轻负迁移效应。
- 标准化与治理:建立LoRA模型的评估标准、发布规范和IP框架,引导社区健康发展。
理解这些问题是更有效地使用LoRA、并为其未来发展指明方向的关键。

(图片来源网络,侵删)