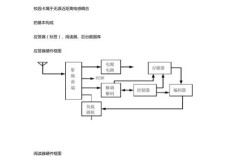
我们将主要使用 Python 语言,因为它在语音处理领域拥有最成熟和最丰富的库。

(图片来源网络,侵删)
目录
- 入门级:关键词识别 - 使用
vosk库- 特点:轻量级、离线、无需深度学习背景。
- 适用场景:简单的命令词识别,如“打开灯”、“播放音乐”。
- 进阶级:语音转文字 - 使用
SpeechRecognition库- 特点:调用云端 API(如 Google, Bing),准确率高,需要网络连接。
- 适用场景:将一段语音内容转换成文字记录。
- 高级/专业级:实时语音识别与处理 - 使用
Python-SoundDevice和SpeechRecognition- 特点:实时捕获麦克风音频流,并进行识别。
- 适用场景:实时会议记录、语音助手交互。
- 核心原理:使用
Librosa进行音频特征分析- 特点:不直接进行“识别”,而是展示声音识别的第一步——特征提取。
- 适用场景:理解声音识别背后的技术,为开发自己的模型打下基础。
入门级:关键词识别 (使用 vosk 库)
Vosk 是一个开源的离线语音识别工具包,非常易于上手,支持多种语言,它预训练了模型,你只需要下载模型文件即可使用。
步骤 1: 安装库和下载模型
# 安装 Vosk pip install vosk # 下载模型 # 访问 https://alphacephei.com/vosk/models 下载对应语言的模型 # 下载中文模型 (vosk-model-cn-0.22) # 将下载的模型文件解压,并记住它的路径,/path/to/vosk-model-cn-0.22
步骤 2: 编写 Python 代码
这个例子会识别一个音频文件(audio.wav)中的关键词。
import os
from vosk import Model, KaldiRecognizer
import wave
import json
def recognize_with_vosk(audio_file_path, model_path):
"""
使用 Vosk 识别音频文件中的关键词。
"""
# 1. 检查模型是否存在
if not os.path.exists(model_path):
print(f"错误:模型路径 '{model_path}' 不存在。")
print("请从 https://alphacephei.com/vosk/models 下载模型。")
return
# 2. 加载模型
print("正在加载模型...")
model = Model(model_path)
print("模型加载完成。")
# 3. 打开音频文件
wf = wave.open(audio_file_path, "rb")
# 4. 检查音频文件格式 (必须是单声道,16位深度)
if wf.getnchannels() != 1 or wf.getsampwidth() != 2:
print("错误:音频文件必须是单声道、16位深度的WAV格式。")
wf.close()
return
# 5. 创建识别器
# sample_rate 必须与音频文件的采样率一致
recognizer = KaldiRecognizer(model, wf.getframerate())
# 6. 逐块读取音频并进行识别
print("开始识别...")
results = []
while True:
data = wf.readframes(4000) # 每次读取4KB的数据
if len(data) == 0:
break
if recognizer.AcceptWaveform(data):
# 获取一个完整的识别结果
result = json.loads(recognizer.Result())
results.append(result.get('text', ''))
# 7. 获取最后的结果(包含未说完的部分)
final_result = json.loads(recognizer.FinalResult())
results.append(final_result.get('text', ''))
wf.close()
# 8. 打印最终结果
final_text = " ".join(results)
print("识别结果:")
print(final_text)
return final_text
# --- 使用示例 ---
if __name__ == "__main__":
# 替换成你自己的模型路径和音频文件路径
MODEL_PATH = "vosk-model-cn-0.22"
AUDIO_FILE_PATH = "audio.wav" # 确保这个文件存在,是单声道WAV格式
recognize_with_vosk(AUDIO_FILE_PATH, MODEL_PATH)
进阶级:语音转文字 (使用 SpeechRecognition 库)
这个库是 Python 语音识别的“瑞士军刀”,它封装了多个主流的语音识别 API,包括 Google Web Speech API、Google Cloud Speech-to-Text、Wit.ai 等,我们这里使用最方便的 Google Web Speech API。
步骤 1: 安装库
pip install SpeechRecognition pydub
注意:
pydub用于处理不同格式的音频(如 mp3),如果只是用 wav 文件,可以不装。(图片来源网络,侵删)

步骤 2: 编写 Python 代码
import speech_recognition as sr
def recognize_with_google(audio_file_path):
"""
使用 Google Web Speech API 识别音频文件。
"""
# 1. 创建一个 Recognizer 对象
r = sr.Recognizer()
# 2. 使用 AudioFile 作为上下文管理器打开音频文件
with sr.AudioFile(audio_file_path) as source:
# 3. 调整噪音(可选,但推荐)
# r.adjust_for_ambient_noise(source)
# 4. 读取音频数据
audio_data = r.record(source)
try:
# 5. 使用 Google Web Speech API 进行识别
# language='zh-CN' 表示识别中文
print("正在使用 Google Web Speech API 进行识别...")
text = r.recognize_google(audio_data, language='zh-CN')
print("识别结果:")
print(text)
return text
except sr.UnknownValueError:
print("无法理解音频内容")
except sr.RequestError as e:
print(f"无法从 Google Speech Recognition 服务请求结果; {e}")
# --- 使用示例 ---
if __name__ == "__main__":
AUDIO_FILE_PATH = "audio.wav" # 确保这个文件存在
recognize_with_google(AUDIO_FILE_PATH)
高级/专业级:实时语音识别
这个例子结合了 sounddevice(用于捕获麦克风音频)和 SpeechRecognition(用于识别),实现一个简单的实时语音识别程序。
步骤 1: 安装库
pip install SpeechRecognition sounddevice numpy
步骤 2: 编写 Python 代码
这个程序会持续监听麦克风,当你说话时,它会识别并打印出结果,为了提高效率,我们只在检测到声音时才进行识别。
import speech_recognition as sr
import sounddevice as sd
import numpy as np
import threading
# 全局变量
is_listening = True
recognizer = sr.Recognizer()
def listen_and_recognize():
"""
在一个单独的线程中运行,持续监听麦克风。
"""
global is_listening
# 获取麦克风的默认采样率
samplerate = int(sd.query_devices(None, 'input')['default_samplerate'])
print("开始监听... (按 Ctrl+C 停止)")
def audio_callback(indata, frames, time, status):
"""这个回调函数会在音频数据可用时被调用"""
if status:
print(f"流状态: {status}")
# 将 numpy 数组转换为 AudioData 对象
# 注意:sounddevice 返回的是 float32, SpeechRecognition 需要 int16
audio_data = sr.AudioData(indata.tobytes(), samplerate, 2)
try:
# 在这里进行识别
# 注意:实时识别非常消耗资源,可能会延迟
# 为了演示,我们直接在这里识别,实际应用中可能需要缓冲
text = recognizer.recognize_google(audio_data, language='zh-CN')
print(f"你说了: {text}")
except sr.UnknownValueError:
# 没有识别到内容,可能是噪音
pass
except sr.RequestError as e:
print(f"识别服务错误: {e}")
# 使用 sounddevice 的 InputStream 来捕获音频
# blocksize=4096 是一个合理的缓冲区大小
with sd.InputStream(callback=audio_callback, blocksize=4096, channels=1, dtype='float32'):
while is_listening:
sd.sleep(100) # 稍微休眠以减少CPU占用
if __name__ == "__main__":
try:
# 在一个新线程中启动监听
listen_thread = threading.Thread(target=listen_and_recognize)
listen_thread.start()
# 主线程等待,直到用户按下 Ctrl+C
while listen_thread.is_alive():
listen_thread.join(0.1)
except KeyboardInterrupt:
print("\n正在停止监听...")
is_listening = False
listen_thread.join()
print("监听已停止。")
核心原理:使用 Librosa 进行音频特征分析
在真正的机器学习模型(如深度学习)进行声音识别之前,第一步是将原始的音频波形(一维数字信号)转换成有意义的特征向量。Librosa 是音频分析领域的标准库。
步骤 1: 安装库
pip install librosa matplotlib
步骤 2: 编写 Python 代码
这个例子将展示如何加载一个音频文件并提取最常用的特征之一:梅尔频率倒谱系数。
import librosa
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
def analyze_audio_with_librosa(audio_file_path):
"""
使用 Librosa 加载音频并提取 MFCC 特征。
"""
# 1. 加载音频文件
# sr=None 表示保持原始采样率
# y 是音频波形 (一维数组)
# sr 是采样率
y, sr = librosa.load(audio_file_path, sr=None)
print(f"音频采样率: {sr} Hz")
print(f"音频时长: {librosa.get_duration(y=y, sr=sr):.2f} 秒")
print(f"音频波形 (前10个样本): {y[:10]}")
# 2. 绘制原始波形图
plt.figure(figsize=(14, 5))
librosa.display.waveshow(y, sr=sr)
plt.title("原始音频波形")
plt.xlabel("时间 (秒)")
plt.ylabel("振幅")
plt.show()
# 3. 提取 MFCC (梅尔频率倒谱系数) 特征
# n_mfcc 是特征的数量,通常为13
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13)
print(f"\nMFCC 特征矩阵的形状: {mfccs.shape}")
print("MFCC 特征矩阵的含义:")
print(" - 行数: n_mfcc (这里是13),代表不同的频率带")
print(" - 列数: 时间帧数")
# 4. 绘制 MFCC 特征图
plt.figure(figsize=(14, 5))
librosa.display.specshow(mfccs, x_axis='time', sr=sr)
plt.colorbar()
plt.title("MFCC 特征")
plt.ylabel("MFCC 系数")
plt.xlabel("时间 (秒)")
plt.show()
# --- 使用示例 ---
if __name__ == "__main__":
AUDIO_FILE_PATH = "audio.wav"
analyze_audio_with_librosa(AUDIO_FILE_PATH)
总结与选择建议
| 技术/库 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Vosk | 离线、轻量、易用、开源 | 准确率不如云端、模型较大 | 嵌入式设备、对隐私要求高、简单的命令控制 |
| SpeechRecognition | 准确率高、支持多种API、简单 | 需要网络、有调用频率限制 | 快速实现语音转文字、记录、字幕生成 |
| 实时识别 (sounddevice) | 实时交互、响应快 | 实现复杂、计算资源消耗大 | 语音助手、实时会议系统、交互式应用 |
| Librosa | 核心基础、功能强大、可视化 | 不直接提供“识别”功能 | 音频特征提取、音频分析、机器学习模型开发 |
对于初学者,建议从 Vosk 或 SpeechRecognition 开始,它们能让你快速实现功能,当你需要更高级的控制或想深入理解底层原理时,再学习 Librosa 和实时处理技术。