可以把整个流程想象成一场人机之间的对话,只不过这个“人”是一个由代码和算法构成的智能体,整个过程可以清晰地分为六个核心步骤,就像一条流水线,每一步都至关重要。

(图片来源网络,侵删)
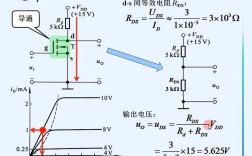
智能语音交互技术原理详解
第一步:语音唤醒
这是整个交互的“启动键”,你不可能让设备随时都在听你说什么,那样太耗电且不安全,它需要一个“名字”来唤醒。
- 技术核心: 关键词唤醒
- 工作原理:
- 模型训练: 工程师会收集大量包含特定“唤醒词”(如“小爱同学”、“天猫精灵”、“Hey Siri”)的音频数据,以及大量不包含唤醒词的背景噪音数据,通过这些数据训练一个深度学习模型(通常是小型、高效的神经网络,如CNN或RNN)。
- 实时检测: 设备上的一个低功耗处理器会持续运行这个模型,实时分析麦克风输入的音频流。
- 判断与激活: 当模型检测到音频流中唤醒词的概率超过某个阈值时,就会判定“唤醒成功”,然后通知主系统,开始进入下一阶段的语音识别。
- 通俗比喻: 就像你在大街上喊朋友的名字,当他听到自己的名字时,才会把注意力转向你,开始听你说话。
第二步:语音识别
这是将人类的“声音”转换成机器能懂的“文字”的过程,是整个交互的基石。
- 技术核心: 自动语音识别
- 工作原理:
- 预处理: 对原始的音频信号进行降噪、端点检测(确定语音的开始和结束位置)等操作,提取出有效的语音片段。
- 声学模型: 这个模型负责将声音特征(如音高、音长、能量等)与音素(语言中最小的发音单位,如汉语的拼音
b,a,i)对应起来,它是一个巨大的神经网络,通过海量“声音-音素”对数据进行训练。 - 发音词典: 提供音素与词语之间的对应关系,音素序列
s-h-u-i可以对应“水”、“谁”等词。 - 语言模型: 这是理解上下文的关键,它负责预测下一个最有可能出现的词语是什么,在“今天天气很……”后面,“好”或“差”出现的概率远大于“苹果”,语言模型基于海量的文本语料库进行训练,理解词语之间的语法和语义关系。
- 解码: ASR系统将声学模型、发音词典和语言模型结合起来,通过复杂的算法(如维特比算法)计算出最有可能的文本序列,这就像是在无数条可能的句子路径中,找到一条概率最高、最通顺的路径。
- 通俗比喻: 就像一个超级速记员,不仅能把你说的每个字都记下来,还能根据上下文自动纠正你口齿不清或说错的地方,最终给出一份通顺准确的文稿。
第三步:自然语言理解
机器虽然得到了文字,但它还不明白这些文字的“意思”和“意图”,NLU就是让机器理解语言的过程。
- 技术核心: 自然语言理解
- 工作原理:
- 意图识别: 判断用户说话的根本目的是什么。“今天北京的天气怎么样?”的意图是“查询天气”;“帮我订一张去上海的机票”的意图是“预订机票”。
- 实体抽取: 从句子中提取出关键信息点,在“帮我订一张明天下午去上海的机票”中,实体包括:
- 时间: 明天下午
- 目的地: 上海
- 物品: 机票
- 数量: 一张
- 情感分析(可选): 分析用户的情绪是积极、消极还是中性,以便提供更人性化的回复。
- 通俗比喻: 这就像一个优秀的秘书,你只要给她一个模糊的指令,她就能立刻明白你到底想干什么,并且把所有相关的关键信息都整理好。
第四步:对话管理
在连续对话或多轮对话中,对话管理模块负责掌控整个交互的流程。

(图片来源网络,侵删)
- 技术核心: 对话状态跟踪、对话策略
- 工作原理:
- 对话状态跟踪: 记录到目前为止对话的所有信息,用户已经说了“A”,系统回复了“B”,用户又说了“C”,状态跟踪器就会记住这些上下文。
- 对话策略: 根据当前的状态和用户的意图,决定下一步系统应该做什么。
- 如果信息不全,就向用户提问(“您想订几点钟的机票?”)。
- 如果信息足够,就调用相应的服务。
- 如果无法理解,就请求澄清或告知无法处理。
- 通俗比喻: 这是整个对话的“导演”,确保对话逻辑清晰、流畅,不会跑偏。
第五步:自然语言生成
当机器通过前面的步骤理解了用户的意图,并执行完相应操作后,需要将结果以自然、流畅的语言回复给用户。
- 技术核心: 自然语言生成
- 工作原理:
- 内容规划: 确定回复中需要包含哪些核心信息,查询天气后,需要包含“天气状况”、“温度”、“风力”等。
- 句子聚合: 将规划好的信息组织成通顺的句子。
- 语言实现: 对句子进行润色,使其更符合人类的表达习惯,比如加入礼貌用语、调整语序等。
- 通俗比喻: 这就像一个发言人,把一堆复杂的数据和结果,用最简单易懂、最自然的方式讲给用户听。
第六步:语音合成
这是最后一步,将机器生成的“文字”转换回“声音”播放出来。
- 技术核心: 文本转语音
- 工作原理:
- 文本分析: 对输入的文本进行分词、断句、确定重音和语调等。
- 声码器: 这是现代TTS技术的核心,它不再使用录音拼接,而是通过一个神经网络(如WaveNet, Tacotron)直接从文本中“生成”人声的声波信号,这使得合成的声音可以做到音色多变、富有情感、语调自然。
- 通俗比喻: 这就像一个顶级的配音演员,能把任何文字稿都读得字正腔圆、富有感情。
一个完整的闭环
我们可以用一个简单的例子来串联这六个步骤:
用户: “小爱同学,明天早上会下雨吗?”

(图片来源网络,侵删)
- 唤醒: “小爱同学”被识别,设备激活。
- 识别: ASR将语音转换成文本:“明天早上会下雨吗?”
- 理解: NLU识别出意图是“查询天气”,实体是“明天早上”。
- 管理: 对话管理模块判断需要调用天气查询服务,并将“明天早上”作为参数。
- 生成: 服务返回结果(如“明天早上,北京,晴,气温20-28度”),NLG将此结果组织成回复文本:“明天早上北京是晴天,不会下雨哦。”
- 合成: TTS将生成的文本转换成语音,播放给用户。
用户听到: “明天早上北京是晴天,不会下雨哦。”
这就是智能语音交互技术从听到说的完整原理,每一步都在不断进步,特别是深度学习的发展,使得语音识别的准确率和语音合成的自然度都达到了前所未有的高度。