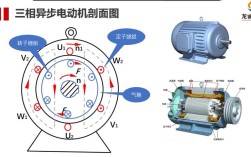
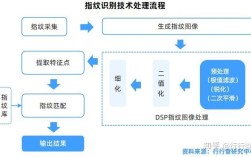
图像识别技术作为人工智能领域的重要分支,近年来在深度学习、大数据和算力提升的推动下取得了突破性进展,已广泛应用于安防、医疗、自动驾驶、工业检测等多个场景,当前,图像识别技术的发展现状可从技术演进、核心突破、应用落地及现存挑战四个维度展开分析。

从技术演进路径来看,图像识别经历了从传统手工特征到深度学习的范式转变,早期方法依赖SIFT、HOG等人工设计的特征提取器,结合SVM、Adaboost等分类器,虽在特定任务中表现稳定,但泛化能力有限且依赖专家经验,2012年AlexNet在ImageNet竞赛中以远超传统方法的准确率夺冠,标志着卷积神经网络(CNN)成为主流,此后,VGG、GoogLeNet、ResNet等模型通过加深网络结构、引入残差连接等技术不断提升精度,ResNet提出的残差单元解决了深层网络梯度消失问题,使网络层数突破百层限制,近年来,Transformer架构凭借其强大的全局建模能力进入图像识别领域,ViT(Vision Transformer)将图像分割为序列块并自注意力机制处理,在大规模数据集上展现出超越CNN的潜力,推动了“CNN+Transformer”混合模型的兴起,如Swin Transformer通过分层设计和移位窗口机制兼顾了局部特征与全局依赖。
核心突破方面,精度、效率与鲁棒性的提升是主要方向,在精度层面,依托ImageNet、COCO等大规模标注数据集,Top-5错误率从2012年的AlexNet的15.3%降至当前EfficientNet等模型的不足1%,部分细分任务甚至超越人类水平,效率优化方面,模型轻量化成为重点,MobileNet、ShuffleNet通过深度可分离卷积减少计算量,使移动端部署成为可能;知识蒸馏技术将大模型知识迁移到小模型,在保持精度的同时降低资源消耗,鲁棒性研究则聚焦对抗样本攻击、域适应等问题,通过数据增强、对抗训练等方法提升模型在复杂环境下的稳定性,例如在光照变化、遮挡、视角偏移等场景下识别准确率提升15%-20%。
应用落地已渗透到各行业核心场景,安防领域,人脸识别技术准确率达99.8%,广泛应用于门禁系统、刑侦追踪,结合动态行为分析实现异常行为实时预警;医疗影像中,AI辅助诊断系统在肺结节、糖尿病视网膜病变检测上准确率超95%,缩短医生诊断时间50%以上;工业领域,基于机器视觉的缺陷检测替代人工,在半导体制造中实现微米级缺陷识别,效率提升3倍;自动驾驶中,多传感器融合(摄像头+激光雷达)实现行人、车辆、交通标志的毫秒级识别,支撑L3级及以上自动驾驶功能,消费级应用如手机摄影的AI场景识别、AR试妆等,通过端侧模型部署实现实时交互。
尽管成果显著,图像识别仍面临多重挑战,数据层面,依赖大规模标注数据导致成本高昂,且跨域泛化能力不足,例如在医疗影像中,不同医院设备差异会导致模型性能下降20%-30%,算法层面,轻量化与精度的平衡仍需突破,当前移动端模型在复杂场景下精度较云端模型低10%-15%;可解释性不足制约了高风险领域应用,如医疗诊断中难以追溯决策依据,伦理问题日益凸显,人脸识别的隐私泄露风险、算法偏见(如对不同肤色人群识别准确率差异)等引发社会关注,需通过技术手段(如联邦学习、差分隐私)与法规规范双重约束。
未来发展趋势将聚焦多模态融合、自监督学习与边缘计算,多模态模型(如CLIP)通过文本与图像联合训练,实现零样本识别,大幅降低数据标注需求;自监督学习方法(如MAE)利用海量无标注数据预训练,减少对标注数据的依赖;边缘计算推动模型向终端设备下沉,5G+AIoT架构下实时图像处理能力将进一步提升,赋能智慧城市、工业互联网等场景。
相关问答FAQs
Q1:当前图像识别技术的准确率已很高,为何仍存在误判?
A1:误判主要源于三方面:一是数据偏差,训练数据若缺乏多样性(如特定肤色、光照不足场景),模型在泛化时易出错;二是对抗样本攻击,微小扰动可使模型输出错误结果;三是复杂场景干扰,如遮挡、运动模糊等导致特征提取不完整,部分领域(如医疗影像)需结合语义理解,而当前模型对上下文逻辑的建模能力有限,可能引发误判。
Q2:图像识别技术在移动端部署面临哪些主要挑战?
A2:核心挑战包括算力限制、内存占用与功耗控制,移动端设备算力仅为服务器千分之一,需通过模型压缩(如剪枝、量化)降低计算量,但过度压缩可能导致精度损失;实时性要求高(如手机拍照场景需毫秒级响应),需优化推理速度;需平衡功耗,避免长时间运行导致设备过热,当前解决方案如TensorFlow Lite、Core ML等框架通过硬件加速(如GPU、NPU)和轻量化模型(如MobileNetV3)逐步缓解这些问题,但极端场景下仍存在性能瓶颈。