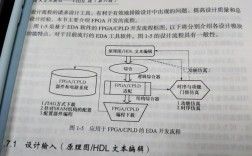
微光图像增强技术是现代光电成像领域的关键研究方向,主要针对在极低照度环境下(如星光、月光或弱光工业场景)获取的图像进行亮度提升、噪声抑制和细节优化,以解决因光照不足导致的图像信噪比低、对比度差、目标难以识别等问题,该技术在安防监控、天文观测、军事侦察、医学成像及自动驾驶等领域具有不可替代的应用价值,以下从技术原理、核心方法、发展历程及挑战等方面展开详细阐述。

微光图像的成像质量受限于传感器性能和光照条件,其本质是光子信号在探测与传输过程中受到噪声的严重干扰,微光图像增强技术需同时解决“亮度不足”和“噪声突出”两大矛盾,核心目标是在提升图像动态范围的同时,尽可能保留原始细节并抑制虚假信息,早期技术主要依赖光学增强手段,如微光夜视仪通过像增强器(Image Intensifier, II)将微弱光子信号转换为电子并通过倍增级放大,再重新显像为可见光图像,这种模拟光电转换技术虽实现了夜间观测,但存在畸变大、信噪比提升有限且无法数字存储等缺陷,随着数字图像处理技术的发展,基于算法的数字微光增强技术逐渐成为主流,其通过数学模型对低照度图像进行非线性映射和噪声滤波,在灵活性和可扩展性上远超传统光学方法。
当前微光图像增强技术主要分为传统算法、基于深度学习的方法及混合增强策略三大类,传统算法中,直方图均衡化(HE)是最基础的亮度增强方法,通过重新分布图像像素的灰度级扩展动态范围,但易导致局部细节丢失和噪声放大,为改进这一问题,自适应直方图均衡化(AHE)和对比度受限自适应直方图均衡化(CLAHE)被提出,通过局部区域处理和对比度限制机制保留细节,但在光照极不均匀的图像中仍可能产生“过增强”现象,在去噪方面,空间域滤波(如高斯滤波、中值滤波)和变换域滤波(如小波变换、块匹配与3D滤波,BM3D)是常用手段,BM3D通过相似块分组与协同滤波,在保持边缘的同时有效抑制高斯噪声,成为传统去噪算法的标杆,但其计算复杂度较高,难以满足实时性要求。
基于深度学习的微光增强技术近年来发展迅猛,核心思路是通过构建端到端的神经网络学习低照度图像到正常光照图像的映射关系,早期方法如Retinex-Net基于Retinex分解理论,将图像分解为反射分量(细节)和光照分量(亮度),分别通过卷积神经网络(CNN)进行优化,再合成为增强图像,后续的Zero-DCE(Zero-Reference Deep Curve Estimation)和KinD等模型则无需配对数据,通过学习像素级曲线映射或无监督损失函数实现增强,降低了数据依赖性,值得注意的是,Transformer架构也被引入该领域,其自注意力机制能有效捕捉长距离像素依赖关系,解决CNN在全局信息建模上的不足,LLNet(Low-Light Network)结合了残差学习和注意力机制,在提升亮度的同时抑制噪声伪影,但训练过程对硬件资源要求较高,且在极端低照度场景下可能出现细节“平滑化”问题。
混合增强策略则融合了传统算法与深度学习的优势,例如先用BM3D进行初步去噪,再通过CNN进行细节恢复,或利用传统方法提供先验知识指导网络训练,这类方法在计算效率和增强效果间取得了较好平衡,但在实时性和泛化能力上仍需进一步优化,多模态融合技术(如红外与微光图像融合)也成为研究热点,通过不同传感器的信息互补提升目标识别率,适用于复杂环境下的安防与军事应用。

尽管微光图像增强技术取得了显著进展,但仍面临多重挑战,极低照度下的光子噪声服从泊松分布,与高斯噪声特性差异显著,现有去噪算法对这类噪声的抑制效果有限,光照不均匀导致的局部过暗或过亮区域难以通过单一模型兼顾,需发展更精细的动态范围压缩技术,第三,深度学习模型的“黑箱”特性使其在可解释性上存在不足,且训练数据依赖大量高质量配对样本,而实际场景中微光与正常光照图像的同步获取难度较大,硬件限制(如传感器尺寸、帧率)也制约了增强算法的实时性能,尤其在无人机、移动终端等嵌入式设备中,需设计轻量化网络模型(如MobileNet、ShuffleNet的改进版)以满足功耗和算力约束。
未来研究将聚焦于以下几个方向:一是探索更高效的噪声建模方法,结合物理成像模型与数据驱动技术,提升对泊松噪声的抑制能力;二是开发无监督或半监督学习框架,减少对标注数据的依赖;三是推动跨模态融合技术的实用化,实现多传感器信息的协同增强;四是结合新型硬件(如事件相机、量子点传感器)的特性,设计针对性的增强算法,突破传统CMOS/CCD的动态范围限制,随着边缘计算能力的提升,实时微光增强系统有望在消费电子领域(如手机夜拍模式、智能眼镜)得到广泛应用。
相关问答FAQs:
-
问:微光图像增强技术与普通图像亮度调整有何本质区别?
答:普通亮度调整(如线性拉伸、伽马校正)仅对像素值进行简单缩放,无法区分有效信号与噪声,易导致噪声放大或细节丢失,而微光增强技术基于成像物理模型,通过噪声抑制、动态范围压缩和多尺度细节恢复等综合处理,在提升亮度的同时尽可能保留真实信息,尤其针对极低照度下的泊松噪声具有针对性优化。 (图片来源网络,侵删)
(图片来源网络,侵删) -
问:为什么深度学习模型在微光增强中效果优于传统算法,但仍存在局限性?
答:深度学习模型能从大量数据中学习复杂的非线性映射关系,自动适应不同场景的光照变化,且通过端到端训练实现全局优化,因此在细节保留和噪声抑制上表现更优,但其局限性主要体现在:一是依赖高质量训练数据,实际场景中配对样本难以获取;二是计算复杂度高,实时性受硬件限制;三是极端低照度下易产生“伪影”(如光晕、细节模糊),需结合物理模型进一步改进。