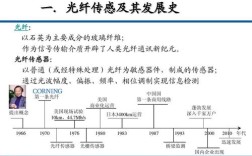
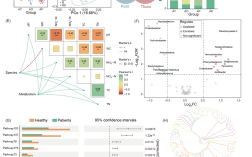
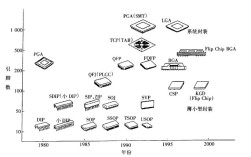
HMM(隐马尔可夫模型)是语音识别领域中最经典且应用广泛的技术之一,其核心思想是通过统计方法将语音信号与文字序列之间的对应关系建模为一个概率过程,语音识别的本质是将连续的声学特征映射为离散的文字符号,而HMM为此提供了数学框架,能够有效处理语音信号的时间动态性和随机性。

HMM在语音识别中的基本原理
HMM是一种基于概率的统计模型,包含两个核心假设:马尔可夫假设(当前状态仅依赖于前一状态)和观测独立性假设(当前观测仅依赖于当前状态),在语音识别中,HMM将语音信号视为观测序列,而将音素、音节或单词等语言单元视为隐状态,识别单词“apple”时,其对应的音素序列/æ//p//l//ə/被视为隐状态序列,而麦克风采集的语音信号经过预处理后提取的声学特征(如MFCC)则是观测序列。
HMM的参数包括三个部分:初始状态概率π(表示每个隐状态在序列开始时的概率)、状态转移概率A(表示从当前状态转移到下一状态的概率)和观测概率B(表示在某个隐状态下生成对应观测序列的概率),这三个参数通过大量带标注的语音数据进行训练(如 Baum-Welch 算法),使模型能够拟合语音信号的统计规律。
语音识别系统中HMM的关键技术流程
语音预处理与特征提取
原始语音信号是模拟信号,需经过预处理(如预加重、分帧、加窗)转化为数字信号,再提取声学特征,常用的特征包括MFCC(梅尔频率倒谱系数),它模拟人耳的听觉特性,通过梅尔滤波器组将频谱转换为梅尔刻度,再通过离散余弦变换(DCT)压缩维度,最终形成包含语音动态信息的特征向量序列,这一步的目的是从语音信号中提取对识别任务最有效的信息,减少噪声和冗余。
声学模型构建
声学模型是HMM在语音识别中的核心应用,用于描述语音特征与音素/单词之间的对应关系,通常采用三音素(Triphone)模型,即考虑音素在左右上下文中的变体(如“-a+t+”中的“a”会受到前一个音素和后一个音素的影响),以解决语音中的协同发音问题,每个三音素对应一个HMM,其状态数通常为3-5个(对应音素的动态变化过程,如起始、稳态、结束),每个状态的高斯混合模型(GMM)用于描述观测概率分布,即通过多个高斯概率密度函数的加权和拟合复杂特征分布。

语言模型与解码
语言模型用于描述单词之间的概率关系,如“语音识别”比“识别语音”在语义上更合理,语言模型会赋予前者更高的概率,常见的语言模型包括N-gram模型,基于大量文本数据统计单词共现频率,解码阶段则是将声学模型和语言模型结合,通过Viterbi算法或束搜索(Beam Search)找到概率最高的隐状态序列(即音素序列),再通过词典将音素序列映射为文字序列,HMM序列可能对应音素序列/æ//p//l//ə/,词典中该音素序列对应“apple”,最终输出识别结果。
HMM的优势与局限性
HMM的优势在于其坚实的数学理论基础和成熟的训练算法,能够有效处理语音信号的时间序列特性,且计算复杂度相对可控,在数据量有限的情况下,HMM仍能保持较好的识别性能,因此在早期语音识别系统中占据主导地位。
HMM的局限性也十分明显:其观测独立性假设忽略了语音特征之间的时序依赖关系(如当前帧特征与前几帧特征的相关性),导致特征建模不够精细;HMM的状态转移概率和观测概率需通过大量数据训练,而数据稀疏时(如小语种或特定领域语音)模型性能会显著下降;HMM与语言模型的独立性假设(声学模型与语言模型分别训练)也限制了整体识别效果的优化。
相关问答FAQs
Q1:HMM在语音识别中为什么需要结合GMM?
A1:HMM的观测概率分布通常需要描述复杂的多模态特征(如同一音素在不同说话人、不同语速下的特征差异),而单一高斯分布难以拟合这种复杂性,GMM通过多个高斯概率密度函数的线性组合,能够更灵活地拟合特征的分布形态,提高声学模型的准确性,HMM与GMM结合(GMM-HMM)成为传统语音识别系统的标准架构。
Q2:HMM被深度学习模型取代的原因是什么?
A2:随着深度学习的发展,HMM的局限性逐渐凸显:HMM依赖手工提取的特征(如MFCC),而深度神经网络(DNN)能够自动从原始语音中学习更抽象、更具判别性的特征;HMM的状态独立性假设和简化的概率模型难以捕捉语音信号的长时依赖关系,而循环神经网络(RNN)、Transformer等模型通过端到端训练,可直接将语音信号映射为文字序列,避免了声学模型与语言模型的分离优化问题,因此在复杂场景(如噪声环境、远场识别)下性能显著优于HMM。