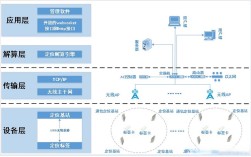
自然语言处理(NLP)作为人工智能领域的重要分支,致力于让计算机理解、解释和生成人类语言,其技术体系涵盖从底层基础到上层应用的完整链条,随着深度学习、预训练模型等技术的发展,NLP已从基于规则和统计的传统方法,逐步发展为数据驱动与知识驱动相结合的智能化范式,形成了多层次、模块化的技术架构。

在自然语言处理技术体系中,基础层是支撑整个系统运行的基石,主要包括语言资源与基础工具,语言资源包括语料库(如大规模文本数据、平行语料库)、词典(如WordNet、同义词林)和知识图谱(如ConceptNet、Wikidata),这些资源为模型训练和知识表示提供了数据基础,基础工具则涵盖分词、词性标注、命名实体识别(NER)等基础NLP任务,这些任务通常作为预处理步骤,为上层应用提供结构化的语言单元,中文分词需解决切分歧义问题,常用方法基于词典匹配(如MMSEG算法)或序列标注(如HMM、CRF);命名实体识别则通过深度学习模型(如BiLSTM-CRF)识别文本中的人名、地名、机构名等实体。
中间层是NLP技术的核心,包括表示学习、模型架构与关键任务技术,表示学习旨在将文本转换为计算机可处理的向量形式,经历了从传统词向量(如Word2Vec、GloVe)到上下文相关表示(如ELMo、BERT)的演进,BERT等预训练模型通过双向Transformer架构捕捉文本上下文信息,通过大规模无标注数据预训练后,再针对下游任务微调,显著提升了模型性能,模型架构方面,循环神经网络(RNN)适合序列建模,但存在长距离依赖问题;Transformer模型通过自注意力机制并行处理序列,成为当前主流架构;而图神经网络(GNN)则能融合知识图谱中的结构化信息,增强语义理解能力,关键任务技术覆盖了NLP的核心领域:文本分类(如情感分析、主题建模)通过卷积神经网络(CNN)或Transformer实现;机器翻译采用编码器-解码器架构(如Transformer),结合注意力机制解决对齐问题;问答系统(如SQuAD)需理解问题语义并从文本中抽取答案;文本生成则包括摘要、对话等任务,常用模型基于Transformer的生成式架构(如GPT系列)。
应用层是NLP技术落地的具体场景,直接面向用户需求,智能客服通过意图识别和对话管理实现人机交互,如基于检索式或生成式的聊天机器人;搜索引擎利用自然语言理解(NLU)技术解析用户查询意图,提升检索相关性;信息抽取从非结构化文本中提取结构化数据,如医疗领域的病历分析;机器翻译打破语言壁垒,支持多语言实时翻译;文本生成辅助创作,如新闻写作、代码生成等,NLP在金融(舆情分析)、法律(合同审查)、医疗(病历分析)等垂直领域也发挥着重要作用,通过领域适配技术提升专业场景下的应用效果。
技术体系中的关键挑战与解决方案推动着NLP的持续发展,数据层面,标注数据成本高的问题通过半监督学习(如自训练)、主动学习(如ALBERT)和小样本学习(如Prompt Learning)缓解;模型层面,大模型的参数效率通过知识蒸馏(如DistilBERT)、模型剪枝和量化优化;可解释性需求通过注意力可视化、因果推断等方法增强;多模态融合则结合文本、图像、语音等信息,提升理解深度(如CLIP模型),NLP技术将向低资源学习、跨语言迁移、情感与常识推理等方向演进,同时更注重伦理与安全性,如避免偏见、保护隐私等。

相关问答FAQs:
-
问:预训练模型(如BERT)如何提升NLP任务性能?
答:预训练模型通过在大规模无标注数据上学习通用语言知识,捕捉词义消歧、句法结构等基础语言规律,下游任务通过微调(Fine-tuning)将预训练参数适配到具体场景,利用迁移学习减少对标注数据的依赖,同时提升模型泛化能力,在情感分析任务中,BERT能结合上下文理解“好”在不同语境中的情感倾向,从而提高分类准确率。 -
问:NLP技术在低资源语言处理中面临哪些挑战?
答:低资源语言(如小语种)因缺乏大规模标注语料和预训练数据,模型性能受限,主要挑战包括:数据稀缺导致过拟合、跨语言迁移效果差、语言结构差异大(如黏着语与屈折语),解决方案包括:利用多语言预训练模型(如mBERT、X-MERT)进行知识迁移,通过跨语言表示对齐实现低资源语言与高资源语言的语义统一,以及采用数据增强(如回译、合成数据)扩充训练集。